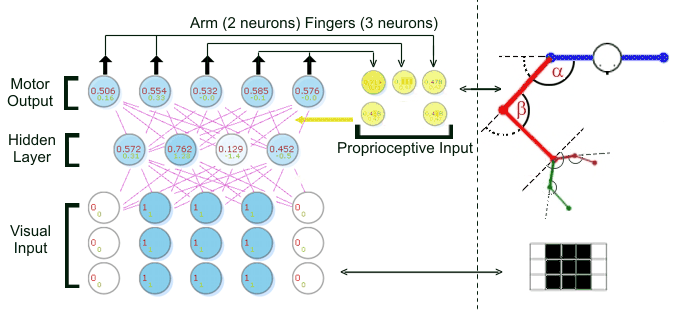
In questa simulazione si insegna alla rete ad afferrare gli oggetti che vengono proposti al suo input visivo con una presa adeguata alle dimensioni dell'oggetto.
Alla rete vengono proposti 2 tipi di oggetti: un oggetto piccolo (1x1 pixel) e un oggetto grande (3x3 pixel). Entrambi gli oggetti possono essere posizionati a destra o a sinistra dello spazio.
La rete neurale viene addestrata per 1.500 generazioni ad afferrare l'oggetto rispettando la sua posizione nello spazio e le sue dimensioni.
La struttura su cui vengono eseguite le simulazioni è definita come nella figura qui sotto: